GitHub Repository: AudioLDM2 - Text-to-Audio and Music Generation
The AudioLDM2 GitHub repository is a valuable resource offering text-to-audio and music generation capabilities. This repository presents a range of features and tools designed to enable users to generate audio content from text inputs and explore music generation possibilities.
Text-to-Audio and Music Generation
AudioLDM2 focuses on providing both text-to-speech and music generation functionalities. The repository includes a text-to-speech checkpoint and a text-to-audio checkpoint that do not rely on FLAN-T5 Cross Attention. This opens up avenues for generating diverse audio content from text prompts.
Open-Source Training Code and Model Enhancements
The project offers open-source training code for both AudioLDM 1 and AudioLDM 2 models. The authors have also put efforts into enhancing model inference speed, ensuring efficient audio generation.
Integration and Web Application
AudioLDM2 supports integration with the Diffusers library and provides resources for setting up a web application. This facilitates seamless integration into different environments and platforms for enhanced accessibility.
Generating Audio Based on Text Prompts
Users can set up the running environment and install AudioLDM2 to initiate audio generation. The repository offers various checkpoint models such as "audioldm2-full," "audioldm2-music-665k," and "audioldm2-full-large-650k," which users can utilize to generate audio from text prompts.
Customization and Control
AudioLDM2 provides users with options to adjust random seeds to enhance model performance on different hardware. Additionally, users have multiple options for controlling generation quality, candidate selection, and guidance scale, allowing for customized audio outputs.
Citation and Future Work
The authors of AudioLDM2 invite users to cite their work when finding the tool useful. They plan to release an upcoming paper titled "AudioLDM Text-to-Audio Generation with Latent Diffusion Models," providing further insights into the tool's capabilities and methodologies.
The AudioLDM2 GitHub repository serves as a valuable resource for those interested in exploring text-to-audio and music generation, offering a comprehensive toolkit and models for generating audio content.
Abstract
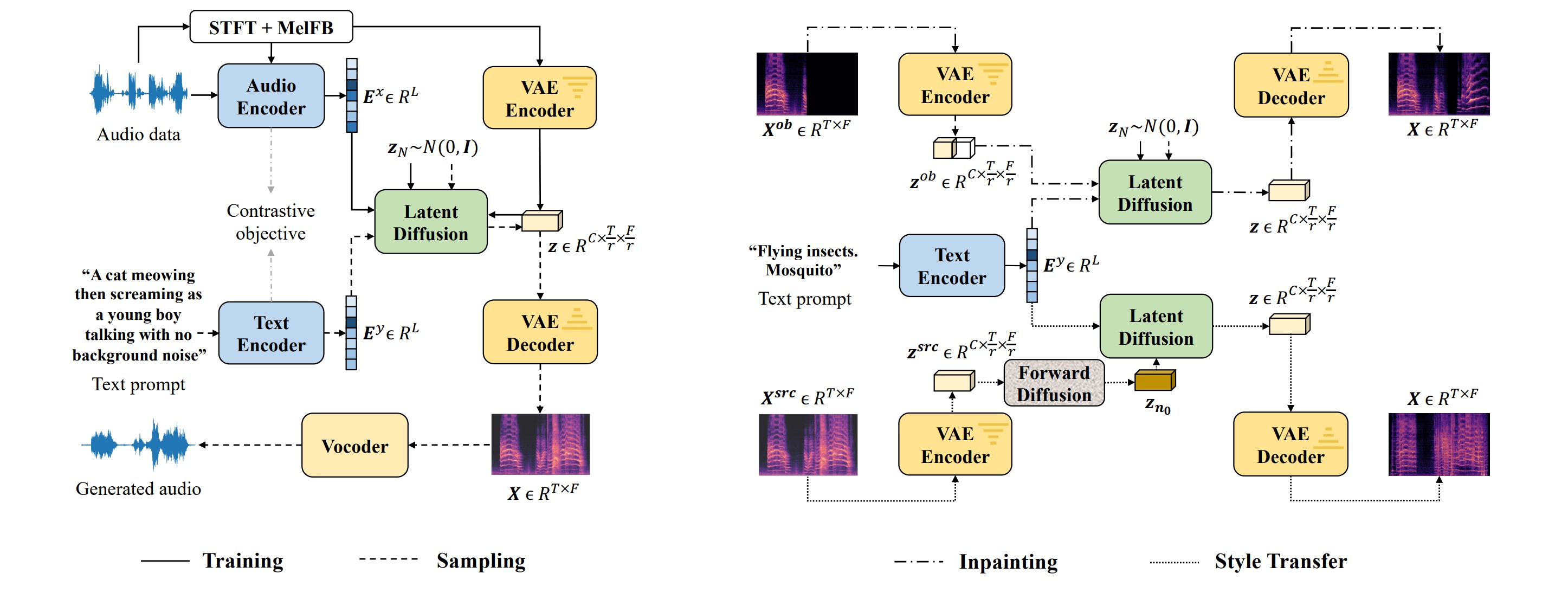
Text-to-audio (TTA) system has recently gained attention for its ability to synthesize general audio based on text descriptions. However, previous studies in TTA have limited generation quality with high computational costs. In this study, we propose AudioLDM, a TTA system that is built on a latent space to learn the continuous audio representations from contrastive language-audio pretraining (CLAP) latents. The pretrained CLAP models enable us to train latent diffusion models (LDMs) with audio embedding while providing text embedding as a condition during sampling. By learning the latent representations of audio signals and their compositions without modeling the cross-modal relationship, AudioLDM is advantageous in both generation quality and computational efficiency. Trained on AudioCaps with a single GPU, AudioLDM achieves state-of-the-art TTA performance measured by both objective and subjective metrics (e.g., frechet distance). Moreover, AudioLDM is the first TTA system that enables various text-guided audio manipulations (e.g., style transfer) in a zero-shot fashion.
Note
AudioLDM generates text-conditional sound effects, human speech, and music.
The LDM is trained on a single GPU, without text supervision.
AudioLDM enables zero-shot text-guided audio style-transfer, inpainting, and super-resolution.
Figure 1: Overview of AudioLDM design for text-to-audio generation (left), and text-guided audio manipulation (right). During training, latent diffusion models (LDMs) are conditioned on audio embedding and trained in a continuous space learned by VAE. The sampling process uses text embedding as the condition. Given pretrained LDMs, the zero-shot audio inpainting and style transfer are realized in the reverse process. The block Forward Diffusion denotes the process that corrupt data with gaussian noise.