
Azure ChatGPT: Private & secure ChatGPT for internal enterprise use.

Chat with Movie, Understand Long Video
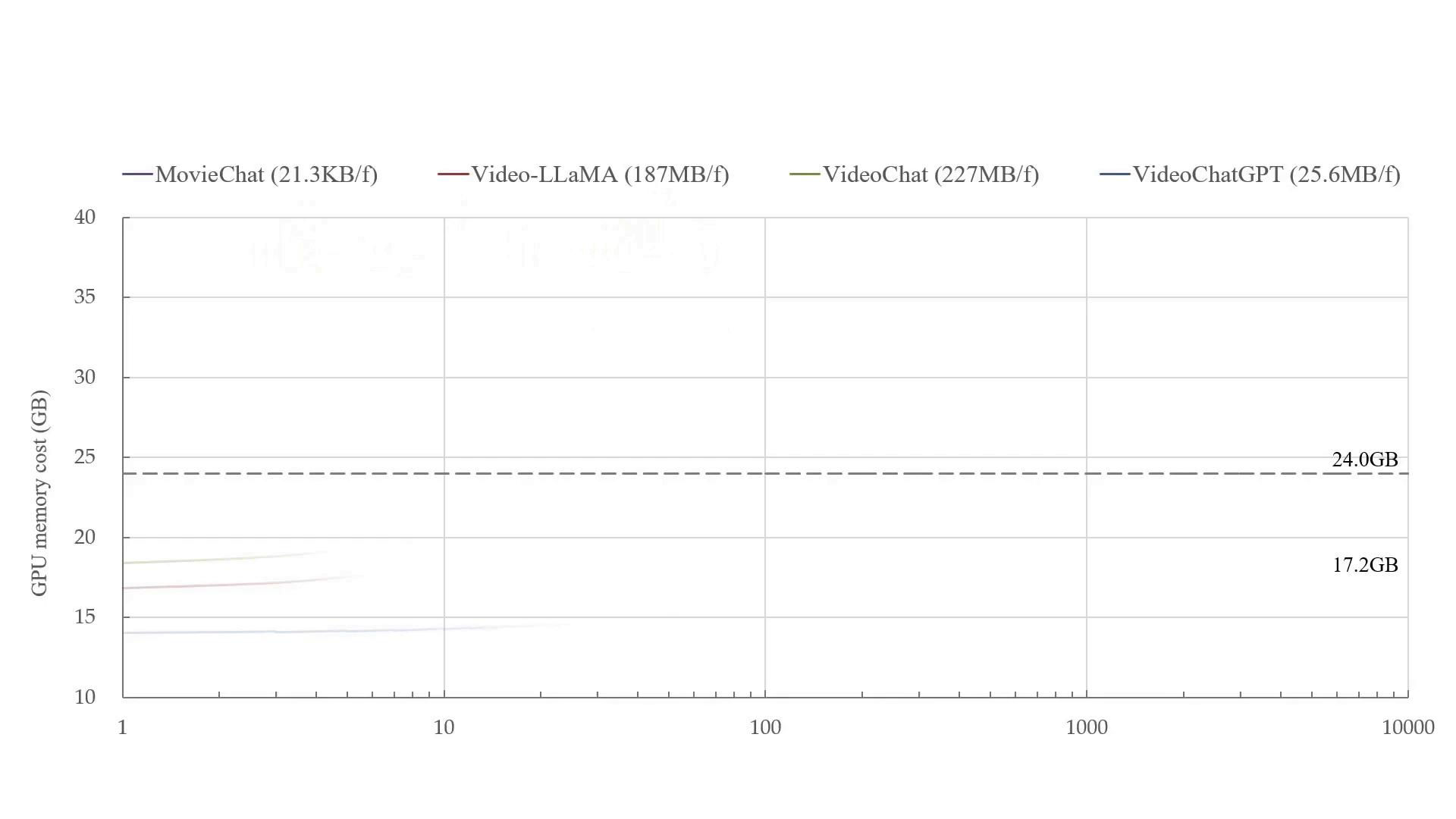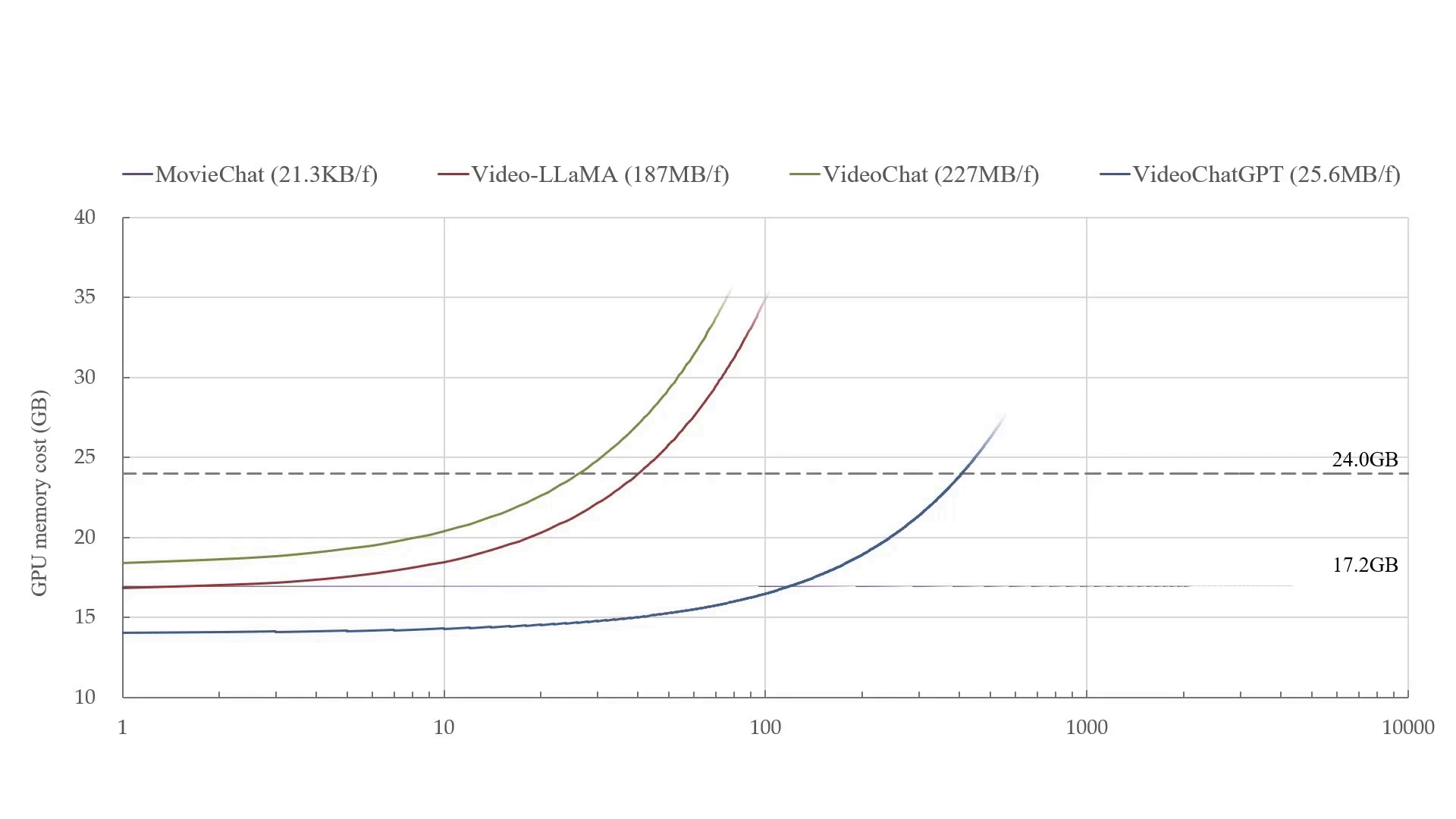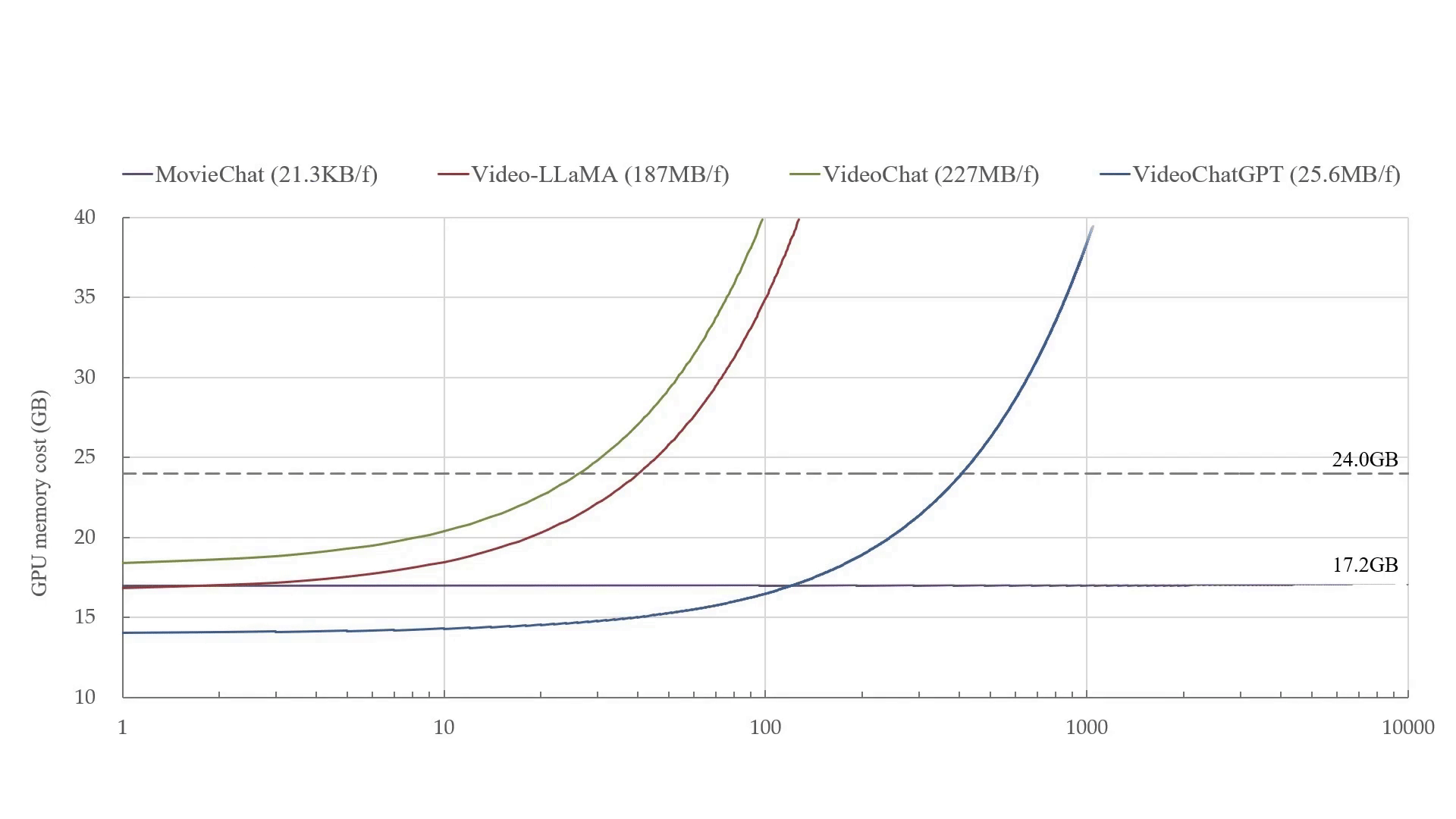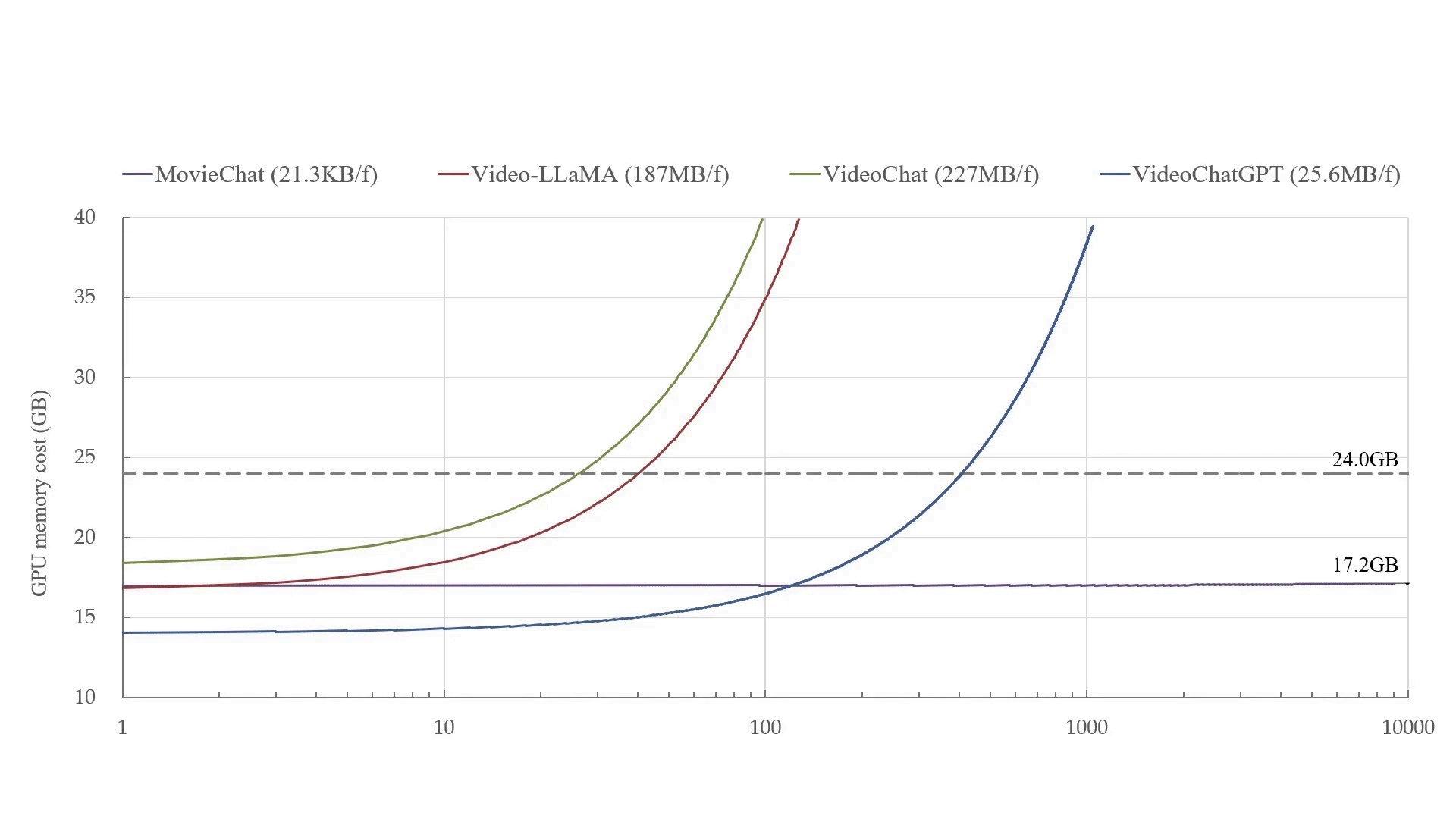

Azure ChatGPT: Private & secure ChatGPT for internal enterprise use.

Discover the power of FlowGPT - the best chat prompt gallery! Get access to the most compelling ChatGPT prompts and revolutionize your communication.

AI content tool that offers various writing features, including blog post creation, resume and job description writing, and more [1]. It provides over 80 templates to assist with different writing tasks [8]. The tool utilizes chat-based AI, similar to ChatGPT, to provide quick answers and has been praised for its template functionality

AskYourDatabase is a plugin for ChatGPT that allows you to chat with your database using natural language, without the need for SQL.

platform that utilizes ChatGPT, an AI-powered language model, to train chatbots using any PDF document. It enables users to create interactive experiences from traditional and static PDFs, making information more accessible and engaging

Blozum is a conversational based AI assistant for businesses which helps customers through the pre-purchase, purchase and post-purchase stages of Product Sales.
Quick compare routes for nearby alternatives.
Compare MovieChat- Chat with Movie, Understand Long Video with Azure ChatGPT- Private & secure ChatGPT for internal enterprise use and jump into the preserved compare route.
Open compare route →Compare MovieChat- Chat with Movie, Understand Long Video with FlowGPT-Best ChatGPT Prompts, AI Prompts Community and jump into the preserved compare route.
Open compare route →Compare MovieChat- Chat with Movie, Understand Long Video with easy-peasy.ai - 80 writing templates with AI assistant and jump into the preserved compare route.
Open compare route →